What is Deep Learning
Note: This is an aggregated article from various blogs website. Aimed at helping people understand Deep learning with ease.
What is Deep Learning?
Deep learning is a type of ML that use a cascade of many layers of nonlinear processing units for pattern analysis (unsupervised) and classification (supervised). Each successive layer uses the output from the previous layer as input.
Learning is based on multiple levels of representations that correspond to different levels of abstraction.

Learning is based on multiple levels of representations that correspond to different levels of abstraction.

Neuron
A neuron forms the basic structure of a neural network. A neuron receives an input, processes it and generates an output which is either sent to other neurons for further processing or it is the final output.


Weights
When input enters the neuron, it is multiplied by a weight. We initialize the weights randomly and these weights are updated during the model training process. Weights represent the priority of the input variable.


Bias
In addition to the weights, another linear component is applied to the input, called as the bias. It is added to the result of weight multiplication to the input. The bias is basically added to change the range of the value. We initialize the bias randomly and these biases are updated during the model training process.
Activation Function
A function that allows Neural Networks to learn complex decision boundaries. Commonly used Functions include sigmoid, tanh, ReLU (Rectified Linear Unit) and variants of these.
sigmoid(x) = 1/(1+e-x)

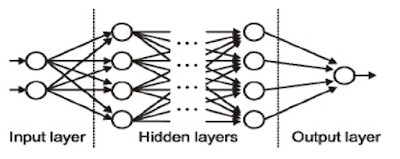
Input / Output / Hidden Layer
The input layer is the one which receives the input and is essentially the first layer of the network. The output layer is the one which generates the output or is the final layer of the network. The processing layers are the hidden layers within the network.
A single neuron would not be able to perform highly complex tasks. Therefore, we use stacks of neurons to generate the desired outputs.
One Hot Encoding

One Hot Encoding
It is a representation of categorical variables as binary vectors.


Softmax
Softmax activation functions are normally used in the output layer for classification problems. The outputs are normalized, to sum up to 1.


Distance between the actual output and expected.




Loss Function
We measure this accuracy of the network using the cost/loss function. The cost or loss function tries to penalize the network when it makes errors.


Gradient Descent
Gradient descent is an optimization algorithm for minimizing the cost.


Forward Propagation
Forward Propagation refers to the movement of the input through the hidden layers to the output layers. This is done when we initially design the Neural Net.
Backpropagation
The error is fed back to the network along with the gradient of the cost function to update the weights of the network.
Batches
During the training process, we divide the input into several chunks of equal size randomly. Training the data on batches makes the model more generalized.
Epochs
1 epoch is a single forward and backward pass of the entire input data.
Learning Rate
The rate at which we descend towards the minima of the cost function.
Vanishing Gradient
During back propagation when the weights are multiplied with these low gradients, they tend to become very small and “vanish” as they go further deep in the network. This can be solved by using activation functions like ReLu.
Exploding Gradient
This is the exact opposite of the vanishing gradient, where the gradient of the activation function is too large. This can be easily solved by clipping the gradient so that it doesn’t exceed a certain value.
Dropout
Dropout is a regularization technique which prevents over-fitting of the network. As the name suggests, during training a certain number of neurons in the hidden layer is randomly dropped.
Comments
Post a Comment